

Deepsearch Inside Agents: How to Get Answers You Can Trust

If your “agent” is basically a chat box that guesses confidently, you don’t have an agent. You have a liability.
Deepsearch functionality is what turns an agent into something you can actually run in operations: it breaks a big question into sub-questions, collects evidence from the outside world, extracts the relevant context, and only then writes the output. In 2026, this pattern shows up everywhere from marketing research to finance ops, because it’s the difference between “sounds right” and “is supported.” (n8n Workflow Template)
This post explains what deepsearch does inside an agent, how the loop works, and a concrete workflow pattern you can copy.
Deepsearch is a loop, not a single search
Deepsearch-enabled agents don’t run one query and call it “research.” They run an iterative loop: generate subqueries, search, extract, learn, repeat, then synthesize. One stored deep research pattern describes it plainly: during the DeepSearch loop, the system generates “learnings” for each subquery and accumulates them across iterations; when the depth limit is reached, it uses the accumulated learnings to generate the final report. (n8n Workflow Template)
Depth and breadth are the two knobs that matter
A DeepResearcher-style workflow explicitly uses depth and breadth parameters to generate AI-generated subqueries. (n8n Workflow Template)
- Breadth controls how many subqueries you fan out into (coverage).
- Depth controls how many iterations you run (persistence).
If you don’t control these, you don’t control cost, latency, or quality. And you’ll only notice once your agent starts timing out or producing a 12-page report nobody asked for.
The “learning accumulation” step is the whole point
The loop’s job isn’t “collect links.” It’s to turn raw pages into structured learnings you can reuse. That same DeepSearch loop pattern explicitly accumulates learnings across iterations and only synthesizes at the end. (n8n Workflow Template)
That’s what makes deepsearch feel different from a normal agent: it’s building a working set of evidence, not riffing.
The most useful deepsearch pattern looks like: Search → Extract → Store
Here’s a concrete “blog deep-search workflow” pattern that’s been captured as an n8n build: it starts from a chat trigger, generates search queries with an LLM, runs Google search via SerpAPI, fetches pages via Jina, extracts relevant context with an LLM, aggregates it, then writes it into Supermemory for reuse. (n8n Workflow Template)
A real node-by-node example (n8n)
One documented pattern (from an n8n workflow used at app.supernodes.ai) lays out the shape end-to-end:
- Chat Trigger
- Generate Search Queries (OpenAI
gpt-4o, temperature0.3) (n8n Workflow Template)
- Parse and Chunk (n8n Workflow Template)
- Split SerpAPI → SerpAPI Official “Google search” → Format Organic Results (n8n Workflow Template)
- Split Jina → Jina HTTP (Bearer Auth) (n8n Workflow Template)
- Extract Relevant Context (OpenAI) → Aggregate Extracted Context (n8n Workflow Template)
- Supermemory Write (
POST api.supermemory.ai/v4/memories,containerTag imported) (n8n Workflow Template)
- In parallel: Supermemory Read (
POST /v4/search, query for “blog tone of voice…”) → format TOV → merge (n8n Workflow Template)
- Generate Blog Article (OpenAI
gpt-4o, temperature0.7) (n8n Workflow Template)
- Google Docs update (insert into a specific doc ID) (n8n Workflow Template)
Two details worth stealing:
- Jina + Supermemory use
genericCredentialType httpBearerAuthin this pattern. (n8n Workflow Template)
- The workflow explicitly stores extracted context back into Supermemory (“Supermemory Write to store memories”), so the next run gets faster and more consistent. (n8n Workflow Template)
“Prepare Context” is the underrated retrieval trick
One captured deep research system includes an AI Agent node called “Prepare Context” that generates a succinct context for each text chunk to improve search retrieval. (n8n Workflow Template)
That’s a practical fix for a common failure mode: you store giant chunks, retrieval gets noisy, and your agent starts citing irrelevant paragraphs. Summarize per chunk before you store or index.
Use deepsearch where the work is “find + decide,” not “write a paragraph”
Deepsearch shines when the agent needs to gather external information and then make a decision or recommendation. The stored research list for 2026 includes concrete deepsearch-enabled agent use cases:
Marketing ops: Google Ads auditing and competitor analysis
A “Google Ads Agent” use case is described as auditing ad spend, analyzing competitor ad copy, and identifying keyword opportunities by integrating with Google Ads and tools like Semrush. (n8n Workflow Template)
This is a classic deepsearch job: multiple sources, lots of surface area, and you want a prioritized output (flag overspend + suggestions).
Content ops: SEO blog optimization from gaps, not vibes
An “SEO Blog Optimizer” use case combines APIs like Firecrawl and Semrush to audit posts for keyword gaps and generate optimization recommendations (keywords, structure, title optimization). (n8n Workflow Template)
Deepsearch matters here because the agent can’t just “suggest improvements.” It needs to look outward (SERPs/competitors) and inward (your post), then reconcile.
Social: research → draft → store
An “X (Twitter) Research and Posting Agent” scans tweets, logs insights, and drafts content in Google Docs. (n8n Workflow Template)
That’s the same pattern as the blog workflow: gather, extract, draft, write somewhere humans already work.
What can go wrong (and how to design for it)
Deepsearch makes agents more capable, but it also gives them more ways to fail.
Failure mode: runaway scope and cost
One set of stored research warns that over 40% of agentic AI projects are predicted to fail by 2027 due to issues like runaway costs and unclear business value. (n8n Workflow Template)
Deepsearch loops are exactly where runaway costs happen: too much breadth, too much depth, too many pages fetched, too many extraction calls.
Design response: make breadth/depth explicit inputs (like the n8n template does), and store intermediate learnings so you don’t pay to re-discover the same facts every run. (n8n Workflow Template)
Failure mode: “collected a lot of text” but didn’t answer the question
The fix is structural: force the agent to create per-subquery learnings and accumulate them, then synthesize at the end. That accumulation loop is explicitly described in the DeepSearch loop research. (n8n Workflow Template)
If you skip the learning step, you’re just building a web scraper with a chat wrapper.
Build this next: deepsearch + multi-agent execution
Deepsearch is already a pipeline. The next step is splitting responsibilities across multiple agents so you can run parts in parallel.
Stored research points to “orchestrated execution with multi-agent systems” where multiple specialized agents collaborate for parallel execution of tasks like analysis, creation, and quality control. (n8n Workflow Template)
A practical extension:
- Agent A generates subqueries and decides breadth/depth.
- Agent B does extraction and produces learnings.
- Agent C does synthesis and writes the final report.
- Agent D does QA (checks whether the output is actually supported by the extracted context).
That’s how you get speed and fewer hallucinations: separation of concerns, not one mega-agent prompt.
Conclusion
If you want an agent you can trust, give it deepsearch: a controlled loop that generates subqueries, extracts evidence, accumulates learnings, and only then writes the output. Start by copying the proven Search → Extract → Store pattern (SerpAPI + Jina + Supermemory), then add depth/breadth controls so you don’t accidentally build a cost bonfire. (n8n Workflow Template)
Sources
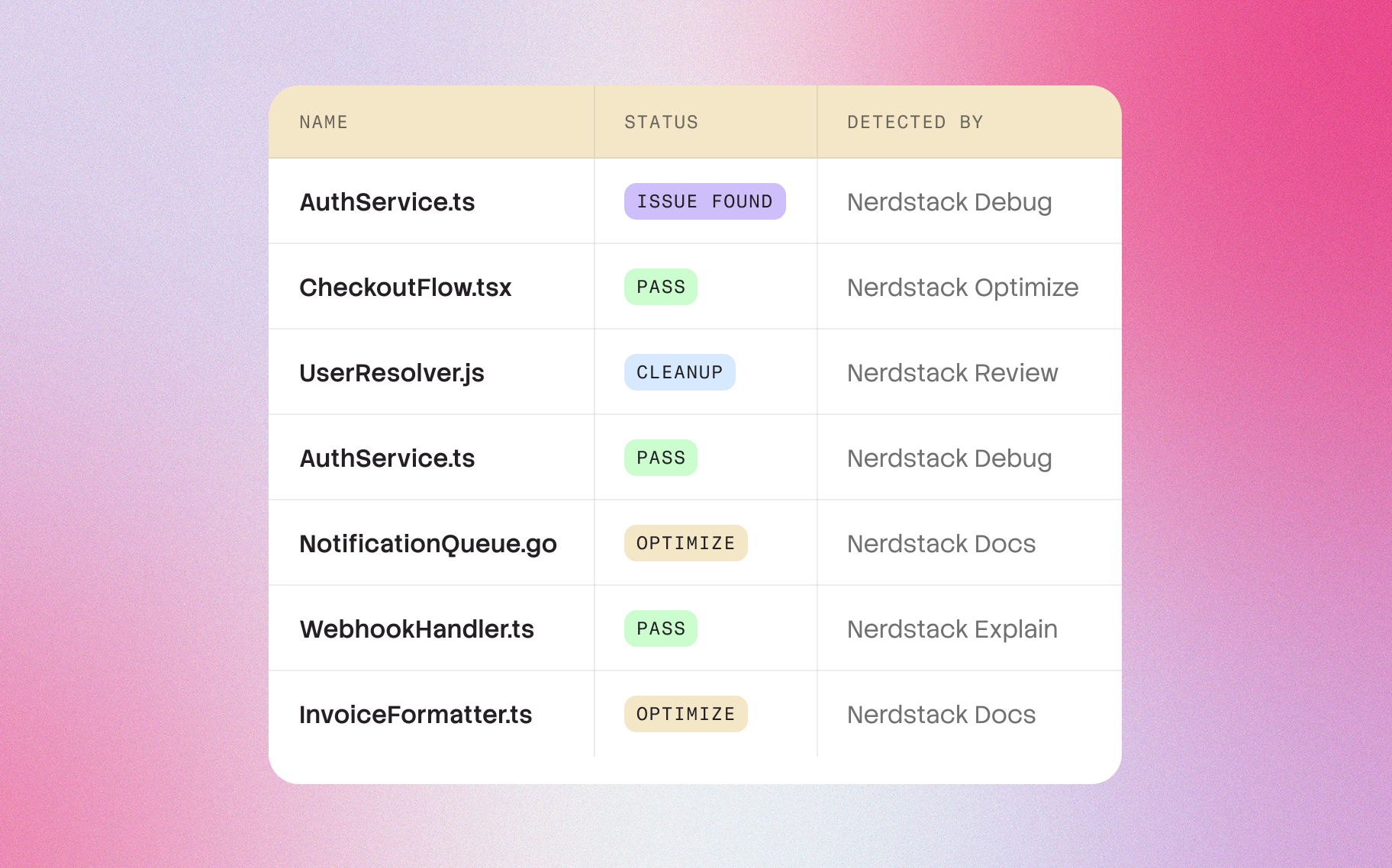
Error-handling logic in a payment flow
Another major learning was how explanations surfaced risky logic patterns that had gone unnoticed for years. By describing code the way a senior engineer would, Nerdstack implicitly highlights inconsistencies, dead paths, unreachable branches, suspicious async chains, or implicit coupling. In one case, a customer discovered a subtle retry bug that had caused unpredictable behavior for months, simply because the explanation pointed out that the function sometimes returned a pending Promise instead of a resolved one.
In another, the system identified that the error-handling logic in a payment flow silently swallowed exceptions that should have been surfaced upstream. These weren’t traditional “bugs”; they were decisions that made sense once but became liabilities over time — exactly the kind of things human-written documentation rarely captures.
Nerdstack dynamically understands
Under the hood, the entire system was built to work with real-world production codebases, not sanitized examples. This means it handles messy patterns, legacy modules, deeply nested components, and frameworks like React, Next.js, Express, Django, Laravel, and more.
Nerdstack dynamically understands how a function interacts with external systems, state, and dependencies. It maps out the control flow, identifies side effects, and extracts behavior across different execution paths. Unlike static analysis tools that often stop at type information, Nerdstack interprets intent — why a function exists, not just what it does syntactically. That difference is what turns explanations from technical summaries into something humans can actually rely on when making decisions.
